機房主機集中管理與監控主機的核心價值與實踐
在當今數字化時代,數據中心機房是企業信息系統的核心命脈。機房內服務器、存儲、網絡設備等主機數量龐大且持續增長,其穩定、高效、安全的運行直接關系到業務連續性。因此,機房主機集中管理與監控已成為現代IT運維不可或缺的關鍵環節,而監控主機正是實現這一目標的核心樞紐與智能大腦。
一、 機房主機集中管理的核心內涵與挑戰
機房主機集中管理,是指通過統一的技術平臺與規范流程,對分散在機房內的各類計算、存儲及網絡資源進行整合式的監控、配置、部署、維護與優化。其核心目標在于:
- 提升運維效率:改變傳統“人跑機房”的被動響應模式,實現遠程、批量、自動化的操作,大幅降低人力成本與操作錯誤率。
- 保障系統穩定:通過7x24小時不間斷的監控,提前預警潛在風險,快速定位并排除故障,最大限度減少業務中斷時間。
- 優化資源利用:全面掌握主機資源(CPU、內存、磁盤、網絡)的使用狀況,為容量規劃、性能調優和成本控制提供數據支撐。
- 強化安全合規:集中管理訪問權限、操作日志和安全策略,滿足審計與合規性要求。
面臨的挑戰主要包括:設備品牌型號異構、監控指標繁雜、海量告警噪聲、虛擬化與云環境融合等。
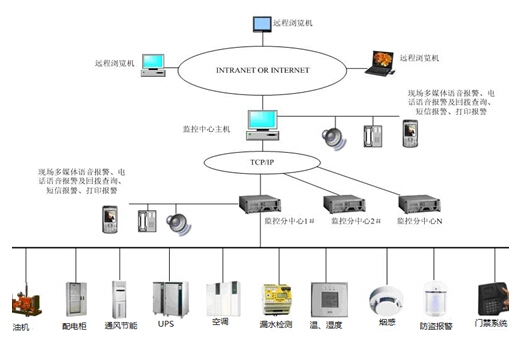
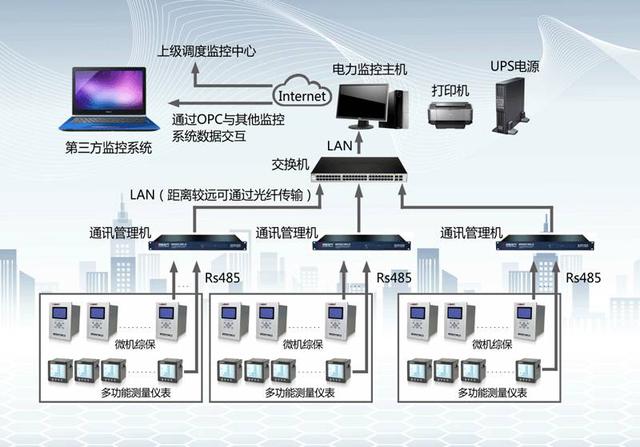
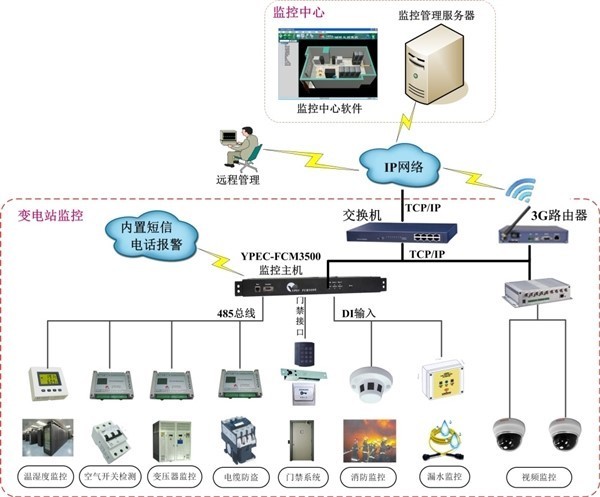
二、 監控主機:集中管理的“神經中樞”
監控主機(通常指部署了專業監控軟件的專用服務器或高可用集群)是集中管理體系的執行核心。它并非簡單的數據收集器,而是一個集數據采集、處理、分析、展示與聯動于一體的智能平臺。
其主要功能模塊包括:
- 自動發現與資產管理:自動掃描網絡,識別并錄入機房內所有IP設備,建立動態更新的資產清單,記錄主機配置信息。
- 多維度數據采集:
- Agent方式:在被監控主機上安裝輕量級代理,采集深度系統指標(如進程、日志、性能計數器)。
- 無Agent方式:通過SNMP、WMI、SSH、IPMI等標準協議,獲取基礎運行狀態、硬件健康信息(如溫度、風扇轉速、電源狀態)。
- 日志采集:集中收集和分析系統、應用及安全日志。
- 實時監控與可視化:
- 性能監控:以圖表形式實時展示CPU使用率、內存占用、磁盤I/O、網絡流量等關鍵指標。
- 狀態監控:監控主機、服務、端口、URL等的可用性。
- 拓撲視圖:動態生成網絡拓撲圖,直觀展現設備間關聯與狀態。
- 智能告警與事件管理:
- 用戶可自定義閾值和告警規則(如CPU持續5分鐘超過90%)。
- 實現告警分級(緊急、重要、警告)、去重、壓縮和升級。
- 支持通過郵件、短信、微信、釘釘等多種渠道通知相關人員。
- 報表分析與容量規劃:定期生成性能、可用性、趨勢分析報表,幫助管理員洞察歷史規律,預測未來資源需求,實現前瞻性管理。
- 自動化響應與聯動:高級監控系統可與運維自動化工具(如Ansible, SaltStack)或ITSM流程對接,實現“監控-診斷-修復”的閉環,例如自動重啟異常服務、擴容磁盤等。
三、 實踐部署的關鍵考量
構建一個高效的機房主機集中監控體系,需要關注以下幾點:
- 架構設計:根據機房規模選擇合適架構。中小型機房可采用單服務器部署;大型或分布式機房應采用分布式、可水平擴展的架構,并確保監控主機自身的高可用性(如主備集群)。
- 監控策略制定:明確“監控什么”和“如何監控”。避免過度監控導致資源浪費和告警疲勞,聚焦于與業務相關的核心指標。建立分級的監控策略。
- 網絡與安全:確保監控網絡通道的暢通與安全,特別是在跨越防火墻或不同網段時。嚴格管理監控系統的訪問權限,加密敏感數據的傳輸與存儲。
- 選型與集成:市場上有Zabbix、Nagios、Prometheus(結合Grafana)等開源方案,以及SolarWinds、Dynatrace、睿象云等商業產品。選型需綜合考慮功能、性能、易用性、擴展性、社區支持及成本,并評估其與現有IT環境的集成能力。
四、 未來發展趨勢
隨著云計算、容器化和人工智能技術的普及,機房主機監控也在向更智能、更云原生的方向演進:
- AIops智能運維:引入機器學習算法,實現異常檢測、根因分析、告警預測,從“人工排查”走向“智能診斷”。
- 云原生與容器監控:深度支持Kubernetes等平臺,監控Pod、Service、Node及微服務鏈路的健康狀況。
- 一體化可觀測性:將監控(Metrics)、日志(Logs)與鏈路追蹤(Traces)數據深度融合,提供端到端的業務洞察。
機房主機集中管理是企業IT運維從粗放走向精細、從被動走向主動的必由之路。 一個功能強大、穩定可靠的監控主機系統,如同為機房配備了一位不知疲倦的“超級管理員”,它不僅是故障的“吹哨人”,更是性能優化與業務保障的“智慧軍師”,為數字業務的平穩高效運行筑牢堅實底座。
如若轉載,請注明出處:http://m.3chj.cn/product/8.html
更新時間:2026-05-24 14:55:15